
What is Data Quality, and How to Enhance it in Research
James Wagner, PhD, Research Professor, Survey Research Center, Institute for Social Research, University of Michigan
We often talk about “data quality” or “data integrity” when we are discussing the collection or analysis of one type of data or another. Yet, the definition of these terms might be unclear, or they may vary across different contexts. In any event, the terms are somewhat abstract -- which can make it difficult, in practice, to improve. That is, we need to know what we are describing with those terms, before we can improve them.
Over the last two years, we have been developing a course on Total Data Quality, available now. We start from an error classification scheme adopted by survey methodology many years ago. Known as the “Total Survey Error” perspective, it focuses on the classification of errors into measurement and representation dimensions. One goal of our course is to expand this classification scheme from survey data to other types of data.
The figure shows the classification scheme as we have modified it to include both survey data and organic forms of data, also known as big data or found data. We find that all forms of data are subject to these same sorts of errors in varying degrees.
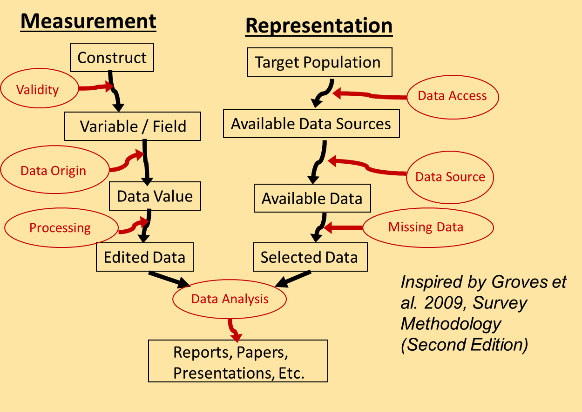
We won’t define all the classes in this post – just two examples.
Data Origin
First, on the measurement side, we look at “Data Origin” as how were the individual values / data points for a given variable (or field) recorded, captured, labeled, gathered, computed, or represented? This could be the process of answering a question, filling a field in an administrative record, or labeling an image in a machine learning context. In the case of labeling images, this could be a human being incorrectly labeling an image. For example, a human being might not note the difference between a cat or a kitten. In some contexts, that difference could be important.
Missing Data
On the representation side, “Missing Data” is a common problem that impacts many types of data. For example, administrative records can be missing key variables or even entire records. Similar things can happen with surveys. These missing data can impact inferences or predictions if the missing values differ from the observed values in important ways.
Using this classification scheme as a way to think about errors can help guide researchers as they consider quality issues. Further, being aware of these issues may also open the door to enhancing the quality along these dimensions! If you’d like to learn more, our new open online courses series focuses on identifying, measuring, and maximizing quality along all of these dimensions.
Read more from Dr. Wagner on his "Survey Methods Musings" blog.

Total Data Quality
This specialization aims to explore the Total Data Quality framework in depth and provide learners with more information about the detailed evaluation of total data quality that needs to happen prior to data analysis. The goal is for learners to incorporate evaluations of data quality into their process as a critical component for all projects. We sincerely hope to disseminate knowledge about total data quality to all learners, such as data scientists and quantitative analysts, who have not had…