
Lecturer IV and Research Fellow
Your browser is ancient!
Upgrade to a different browser to experience this site.
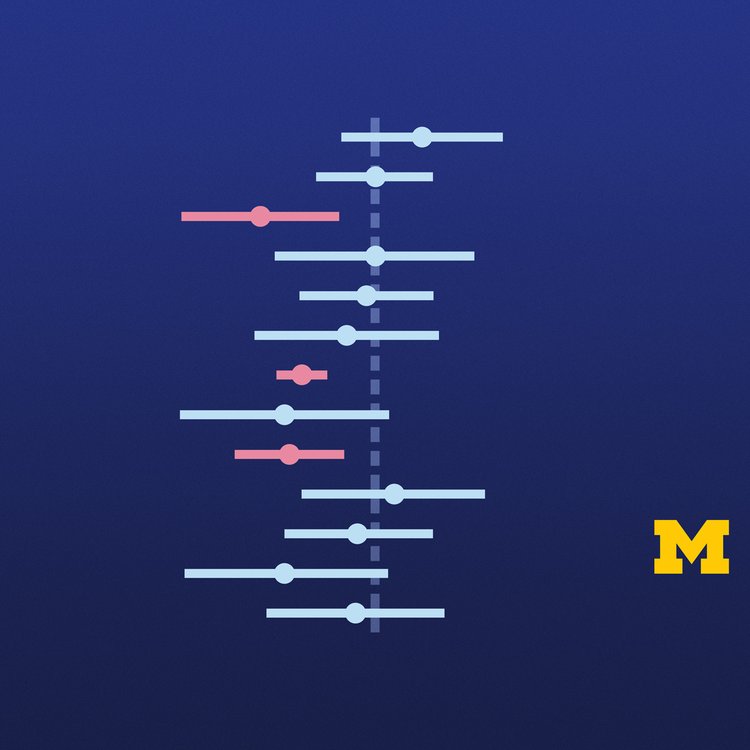
In this course, we will explore basic principles behind using data for estimation and for assessing theories. We will analyze both categorical data and quantitative data, starting with one population techniques and expanding to handle comparisons of two populations. We will learn how to construct confidence intervals. We will also use sample data to assess whether or not a theory about the value of a parameter is consistent with the data. A major focus will be on interpreting inferential results appropriately.
At the end of each week, learners will apply what they’ve learned using Python within the course environment. During these lab-based sessions, learners will work through tutorials focusing on specific case studies to help solidify the week’s statistical concepts, which will include further deep dives into Python libraries including Statsmodels, Pandas, and Seaborn. This course utilizes the Jupyter Notebook environment within Coursera.
Inferential Statistical Analysis with Python, the second course in the Statistics with Python series, builds skills in statistical inference using real-world data and Python programming. Learners explore confidence intervals, hypothesis testing, and interpretation of inferential results while applying concepts through hands-on labs using Jupyter Notebooks and Python libraries such as Pandas, Statsmodels, and Seaborn.
This abbreviated syllabus description was created with the help of AI tools and reviewed by staff. The full syllabus is available to those who enroll in the course.
Module 1: Overview & Inference Procedures
Module 2: Confidence Intervals
Module 3: Hypothesis Testing
Module 4: Learner Application
Learners must earn an overall passing score based on multiple assessments. The course grade is based on three quizzes worth 10% each (30%), a module one Python assessment (10%), two additional Python assessments worth 20% each (40%), and a peer-review assessment worth 20%.
Lecturer IV and Research Fellow

Professor

Research Associate Professor
Course content developed by U-M faculty and managed by the university. Faculty titles and affiliations are updated periodically.
Intermediate Level
High school algebra, successful completion of Course 1 in this specialization or equivalent background
